USENIX Security 2020.
Abstract
本文研究了对于黑盒的ML模型的输出在更新前后的更改是否会泄漏用于执行更新的数据的信息。这引出了一种针对黑盒模型的新攻击,这种信息的泄漏会严重损害ML模型拥有者/提供者的intellectual property和数据隐私。和membership推断攻击相比,本文采用了encoder/decoder formulation,可以推断从详细的特征到数据集的完整重构。
本文采用了混合生成模型(BM-GAN),它是基于GAN的,但是包含了一个可以生成准确sample的重构损失(reconstructive loss)。实验表明可以有效地预测数据集特征,甚至是challenging conditions下的完整重构。
Introduction
主要研究问题:大概是说,在线学习中,模型是增量更新的,这一过程中,某个数据集被用来训练前和训练后,对同样的sample会产生不同的输出,本文研究这个不同的输出,会不会泄漏被用来更新模型的数据集的信息。
针对黑盒模型,提出了4种不同的攻击,可以被分为两类:single-sample attack和multi-sample attack。
四种攻击中,有两种旨在重构updating set(每类一种)。理论上,membership推断可以被用来重构黑盒模型的数据集,但是,membership推断并不适用扩展于真实世界中的,因为敌手需要收集大量数据样本,而该样本恰好包含目标模型的所有训练集样本。
General Attack Construction. 本文的四种攻击都基于通用的结构,可以概括为encoder-decoder style。encoder是由多层感知机(MLP)以不同的目标模型的输出(称作posterior difference)为输入,而decoder针对不同的攻击产生有关更新集的不同类型的信息。
为了获取到posterior difference,随机选择了固定的数据样本,称为探测集合(probing set),用来探测不同版本的目标模型。然后,计算两次posterior集合的不同,作为四种攻击encoder的输入。
Single-sample Attack Class. 包含两种攻击: single-sample label inference attack和single-sample reconstruction attack。
前者用来预测单个样本的标签,对应的decoder由一个两层感知机实现。
后者是对更新数据集的重构。首先通过不同的数据集合训练一个autoencoder(AE),然后将AE的decoder转移到本文的攻击模型中作为样本重构器。
Multi-sample Attack Class. 也包含两种攻击:multi-sample label distribution estimation attack和multi-sample reconstruction attack。
前者估计updating set的标签分布,decoder用多层感知机实现,拥有一个全连接层和一个softmax层。用KL散度作为模型的损失函数。
后者用来生成updating set的所有数据集。decoder由两部分组成,第一部分用来学习数据的分布,用BM-GAN实现,它引入了一个”Best Match”损失来确保每个样本都被重构了。第二部分decoder依赖于机器学习中的聚类,将BM-GAN生成的数据聚类,用中心节点作为重构的样本。
实验结果都贼吊!
Threat Model
ML模型都是黑盒的,敌手只能通过查询获得输出。
敌手可以通过之前的一些工作,得到模型的参数和超参数,构建出和目标模型一样的影子模型。(这知道参数和超参,还叫啥黑盒,实验是利用之前工作推断出的近似参数还是直接用了模型现成的参数呢?)
通过这两种信息模拟目标模型的行为来推导训练数据。
General Attack Pipeline
如图1所示,攻击分为三步:
- adversary生成攻击输入(posterior difference);
- encoder把posterior difference转化成隐向量;
- decoder把隐向量解码,针对不同攻击产生更新集的不同信息。
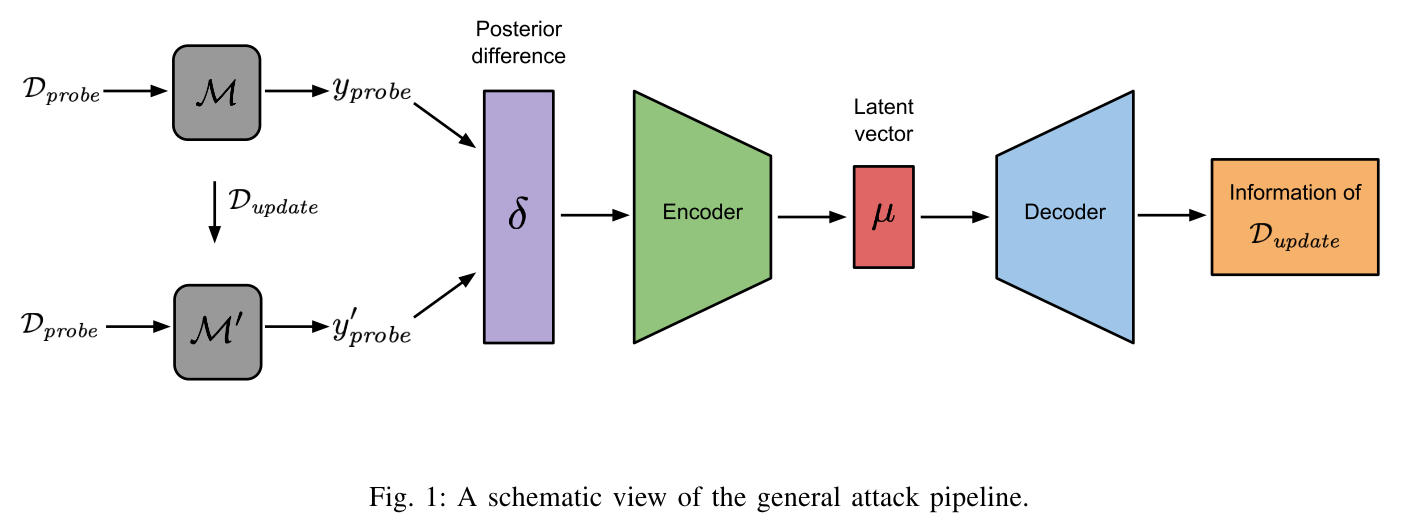
posterior difference. 为了生成posterior difference,敌手随机选择一些数据作为探测集,用$D_{probe}$表示。然后向模型进行查询,分别生成探测集对应的标签$y_{probe}$和$y_{proble}^{\prime}$。$\delta = y_{probe}-y_{probe}^{\prime}$表示posterior difference。$\delta$的维度是$D_{probe}$个数和数据集种类数目的乘积。本文选用了100个样本,两种数据都是10类,因此维度是1000。
Encoder. 是一个多层感知机,层数取决于$\delta$的维度。由于维度固定1000,因此encoder中用两个全连接层,第一层是128维的向量,第二层64维。
Decoder. 每种attack是不同的。
Shadow Model. 用来模拟目标模型的。
By controlling the training process of the shadow model, the adversary can derive the ground truth data needed to train her attack models.
敌手需要知道目标模型的结构和与目标数据集相同分布的一个本地数据集。
(你怎么能知道训练数据的分布?)
为了训练影子模型$M_{shadow}$,首先构造一个和目标模型结构一样的ML模型。然后取本地数据集中的一部分$D_{shadow}$(剩下的是$D_{probe}$),分为两部分$D_{shadow}^{train}$和$D_{shadow}^{update}$,前者用来训练影子模型,后者分为m个数据集,每个数据集中的数量是依赖于不同攻击的。比如,single-sample攻击中每个子数据集只包含一个数据。敌手会利用m子数据集通过更新$M_{shadow}$生成m个新的影子模型。
接下来敌手会用$D_{probe}$来探测影子模型,并且计算posterior difference $\delta_{shadow}^1 \dots \delta_{shadow}^m$。结合对应的shadow updating set的真实信息就可以推断出它攻击模型的训练数据。
Single-Sample Attacks
#####Single-sample Label Inference Attack
decoder构造:全连接层加上一个softmax来把隐向量转化成label。
通过上述方法生成影子模型,然后利用影子模型生成ground truth data,来训练attack model。损失函数用交叉熵,
\[L_{CE} = \sum_{i} l_i\log(\hat{l_i})\]其中$l_i$是label i的真实概率,$\hat{l_i}$是预测概率,用ADAM做的优化。
#####Single-sample Reconstruction Attack 基于autoencoder(AE)来构造update dataset。
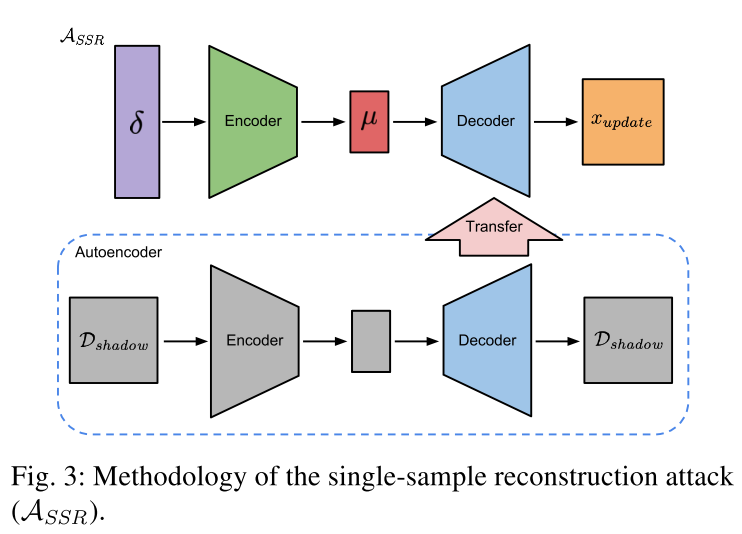
AE训练好后,敌手把AE的decoder加到攻击模型的encoder后边。
attack model的训练分为两阶段:
- 敌手用shadow dataset训练AE;
- 用和single-sample label inference attack相同的步骤训练attack model。
先预训练AE的decoder,然后再和attack model的encoder一起训练,损失函数用MSE:
\[L_{MSE} = \Vert \hat{x}_{update} - x_{update} \Vert_2^2\]其中$\hat{x}_{update}$是预测的data sample,用ADAM做优化器。
(这里的x应该是一个向量,MNIST数据集中是0和1的,用到其他地方也能好用么?)
放个论文中的图吧

our attack indeed learns to construct the specific updating data sample instead of a general representation of samples affiliated with the same label as the target updating sample.
###Multi-Sample Attacks
Multi-sample Label Distribution Estimation Attack Attack
目标是估计update set中样本label的分布,可以看作是single版本的泛化。
decoder结构和single版本的一样。用KL散度作为目标函数。
We assume the adversary knows the cardinality of the updating set.
Multi-sample Reconstruction Attack Attack
之前用的AE不能生成多个samples,所以用GAN。但是本攻击的目标是根据posterior difference $\delta$重构$D_{update}$,标准GAN做不到,因此提出了混合生成模型,BM-GAN。
BM-GAN. decoder作为BM-GAN的生成器,类似于Conditional GAN中做的那样。但是cGAN容易mode collapse。为了解决这个问题,引入了重构损失(reconstruction cost)。然而,对于给定的$\delta$和噪声向量$z$,应该让BM-GAN去重构哪个点呢?因此,本文给了GAN极大的自由,让它自己选择data sample去重构。用基于”Best Match”的目标函数去实现这个:
\[L_{BM} = \sum_{x\in D_{update}} \min_{\hat{x}\sim G} \Vert\hat{x}-x\Vert _2^2 + \sum_{\hat{x}}\log(D(\hat{x}))\]其中,$\hat{x}\sim G$表示给定隐向量$\mu$和noise sample $z$,BM-GAN生成的samples。前半部分就是标准的MSE,
However, unlike the standard MSE reconstruction cost, given a data sample $x \in D_{update}$, the cost is based only on the generated sample $\hat{x}$ which is closest to the data sample $x\in D_{update}$.
(上面这句没看懂。。)
这就允许BM-GAN在没有得到确切的$(\delta, z)$对和样本之间的map时,仍可以对$D_{udpate}$进行重构。最后,判别器D保证了$\hat{x}$和真实数据的不可区分性。
Possible Defences
Adding Noise to Posteriors
考虑直接给posterior difference上加扰动,但是你不可能直接知道敌手什么时候用什么数据来探测你的模型。因此可以直接在每次通过model进行query后加一个噪声。本文尝试加入均匀分布的噪声,实验表明可以使得某些攻击有一个明显的下降。但是对于multi-sample重构攻击,效果却不明显,可能是因为noise vector z是BM-GAN输入的一部分,因此attack model对noise input更加鲁棒。(我觉得有疑问)
Differential Privacy
DP设计就是用来降低本文攻击效果的,但是需要强调DP依赖于privacy budget,对模型本身的性能影响也很大。
Conclusion
目前只针对了online learning场景。
选探测集时是随机选的,用一定的方法选可能会提高供给效率,作为future work。
encoder、decoder和BM-GAN的结构见论文。
