https://www.youtube.com/watch?v=o6HBIGzQfJs
youtube看到的视频,底下有个评论说讲的清楚,记一些有用的结论留存。









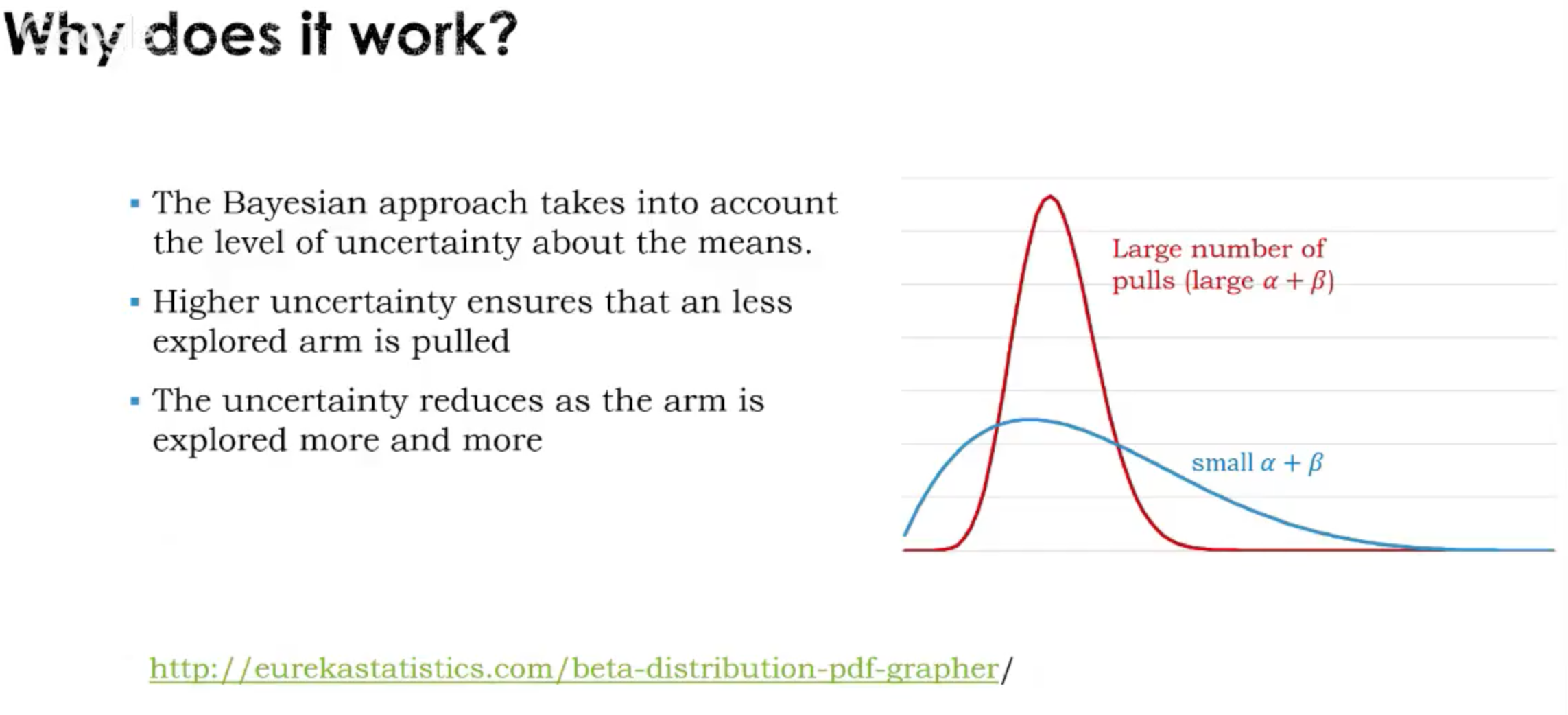
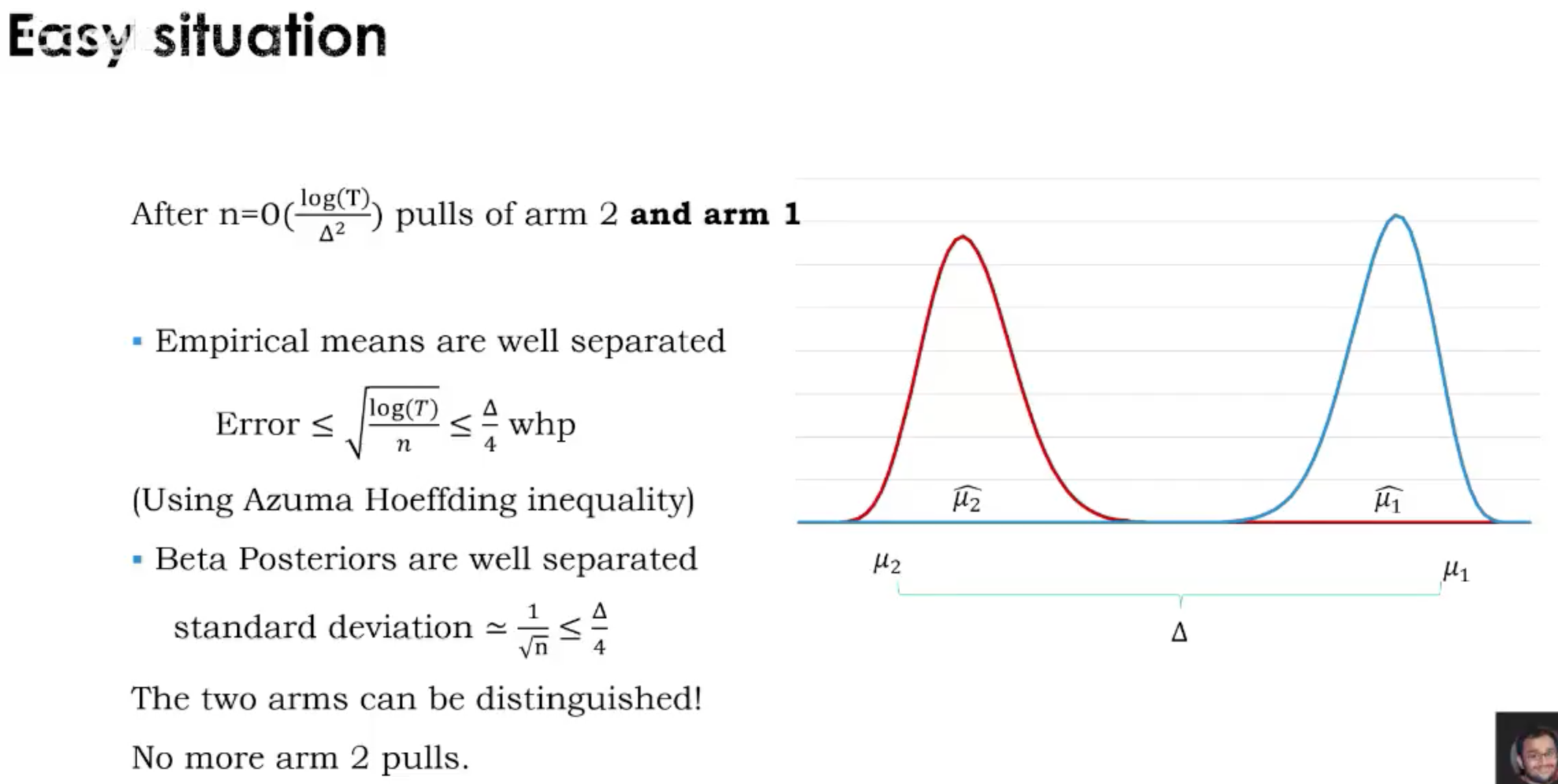
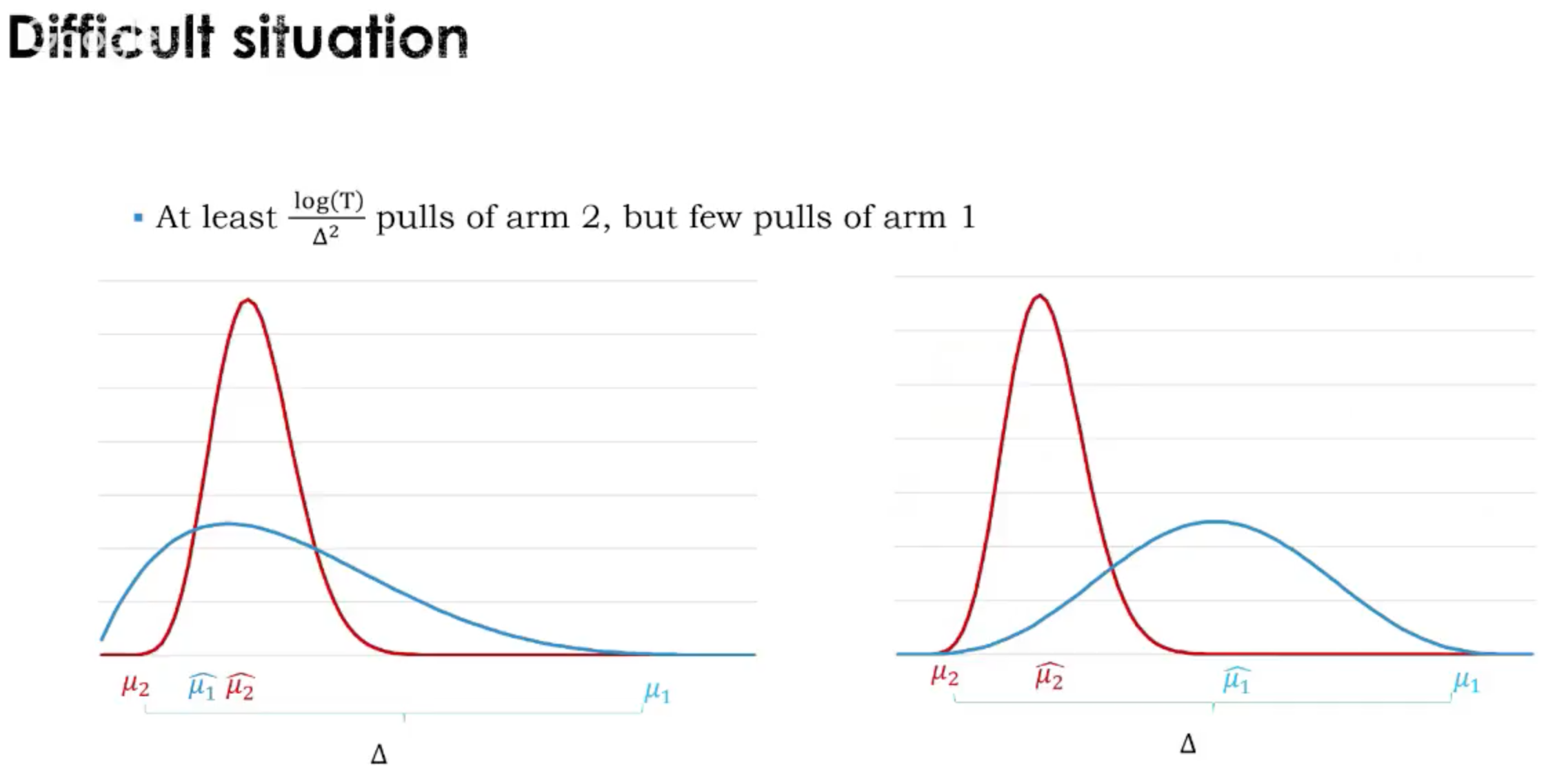




这种情况下,arm对应的reward不再是固定的,取决于在时刻t,arm $i$所面对的context,也就是$x_{i,t}$



结果不依赖于arm的个数。$d$是$\theta$的维度。只假设了分布是bounded或者sub-Gaussian noise(这个是什么意思?)



用Dirichlet分布作为后验分布,有n个参数,如果有某个状态发生变化,就把相应的参数增加。



