Introduction
苹果Differential Privacy Team写的Learning with Privacy at Scale。介绍了苹果是怎么把差分隐私用在iOS中的。
Our system is designed to be opt-in and transparent. No data is recorded or transmitted before the user explicitly chooses to report usage information. Data is privatized on the user’s device using event-level differential privacy [4] in the local model where an event might be, for example, a user typing an emoji. Additionally, we restrict the number of transmitted privatized events per use case. The transmission to the server occurs over an encrypted channel once per day, with no device identifiers. The records arrive on a restricted-access server where IP identifiers are immediately discarded, and any association between multiple records is also discarded. At this point, we cannot distinguish, for example, if an emoji record and a Safari web domain record came from the same user. The records are processed to compute statistics. These aggregate statistics are then shared internally with the relevant teams at Apple.
用了local-DP,传输是每天一次,通过加密隧道传输的,去掉了唯一标识的信息比如IP,去掉了多个记录之间的相互联系。这样看来的确是很强的保护了隐私。
We focus on the problem of estimating frequencies of elements — for example, emojis and web domains. In estimating frequencies of elements, we consider two subproblems. In the first, we compute the histogram from a known dictionary of elements. In the second, the dictionary is unknown and we want to obtain a list of the most frequent elements in a dataset.
苹果主要关注对于emojis表情和web domians的使用频率。为此考虑两个子问题,计算已知字典的直方图和未知字典的最高频率使用的元素。
System Architecture
系统架构包括设备端(device-side)和服务器端(server-side)对数据的处理。在设备端,隐私化步骤保证了原始数据是符合DP的;服务端的数据处理可以切分成 ingestion 和 aggregation 两步。
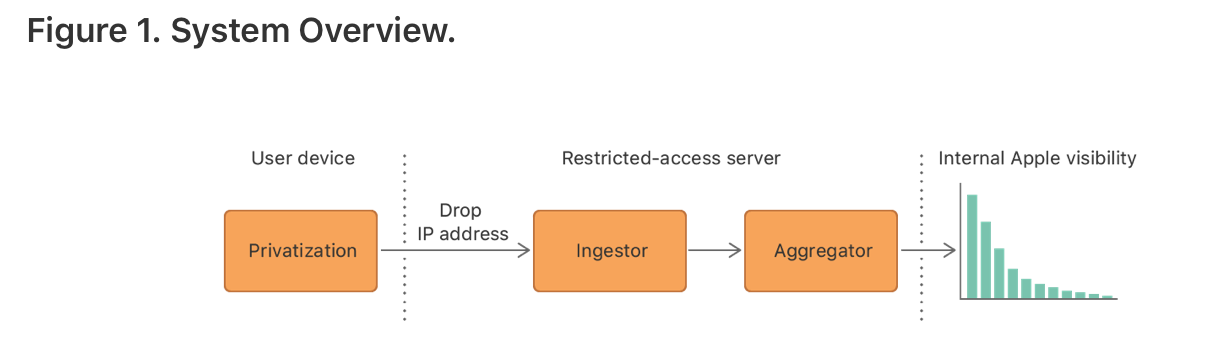
Privatization
用户可选是否开启共享隐私数据。对于开启共享的用户,为每个event设置一个隐私参数$\epsilon$。此外,还限制了用户每天可以传输的隐私数据数量。
Our choice of $\epsilon$ is based on the privacy characteristics of the underlying dataset for each use case. These values are consistent with the parameters proposed in the differential privacy research community, such as [5] and [6].
Moreover, the algorithms we present below provide users further deniability due to hash collisions. We provide additional privacy by removing user identifiers and IP addresses at the server where the records are separated by use case so that there is no association between multiple records.
去掉了用户标识和IP,按照use case划分records,这样可以切断记录之间的联系。
设备上产生一个event时,它就是$\epsilon$-local DP的,然后并不是立即发往服务器,而是通过苹果的data protection [1] (一种把数据加密存储在内存的技术) 把数据暂时存储在设备上。在根据设备条件延迟一段时间以后,系统从上述records中随机采样一些然后发送给服务器。这些记录不包括设备ID和event发生的时间戳等信息。通过TLS加密隧道发送到服务器。如图2所示。
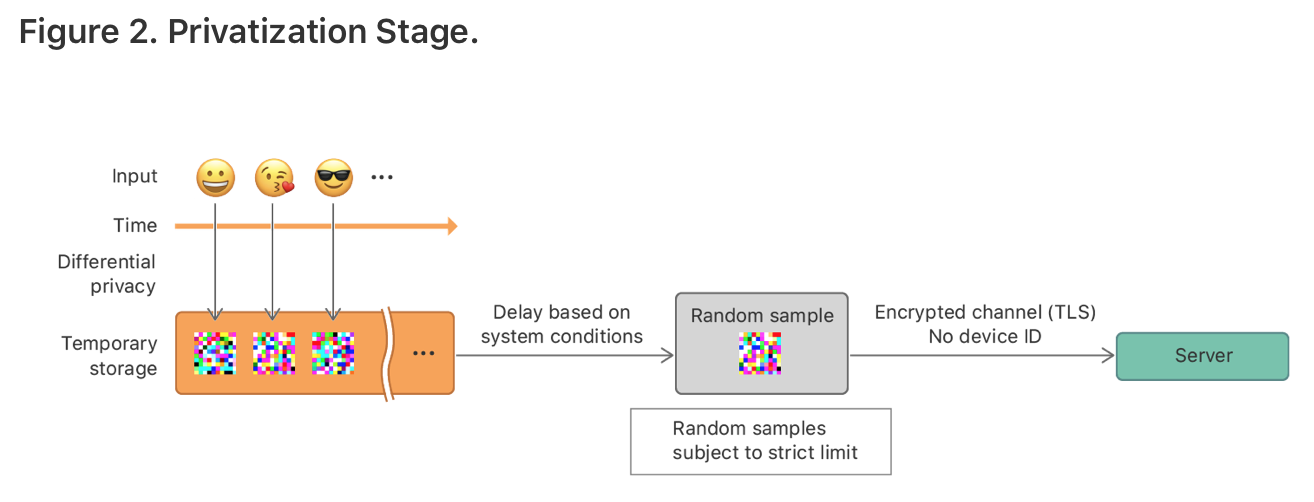
(一点疑问,这个图看起来是经过加密了才发送到服务端的,那还用差分隐私做什么?)

如图3所示为受欢迎的emoji表情统计算法的一个采样片段。records是一个128字节的16进制字符串。
Ingestion and Aggregation
私有化记录在进入Ingestor之前首先被去掉其IP地址。 然后,Ingestor从所有用户收集数据并批量处理它们。 批处理过程删除元数据,例如收到的私有化记录的时间戳,并根据用例分隔这些记录。 在将输出转发到下一阶段之前,Ingestor还随机地置换每个用例中私有化记录的顺序。
Aggregator从Ingestor中获取到records,为每个用例生成一个符合DP的直方图。计算统计信息时,来自多个用例的数据永远不会合并。在这些直方图中,仅包括计数高于规定阈值T的域元素。
(疑问:这个用例是指什么,每个人的统计信息吗?)
Algorithms
Private Count Mean Sketch
The Private Count Mean Sketch algorithm (CMS) 有两个步骤:客户端处理和服务器端聚合。
一个例子:假设某个用户访问了www.example.com这个网址。
客户端算法会从k个hash函数中${h_1, h_2, \dots, h_k}$随机选一个,假设选了$h_2$。$h_2(www.example.com) = 31$。然后用一个长度为m的向量对31进行one-hot编码,第31位为1。为了保证DP,这个向量的每一位都以$\frac{1}{e^{\epsilon/2}+1}$的概率进行flip (1变为0,0变为1) 操作。最后这个向量和hash函数的index $j$被发送到服务器。
服务器端算法通过聚合上述来自设备端的隐私向量构造一个sketch matrix M。该矩阵有k行,每行是一个hash函数;m列代表从客户端传输的长度为m的向量。
当records到达服务器时,算法把privatized vector加入到第$j$行。然后适当地缩放M的值,使得每行有助于为每个元素的频率提供无偏估计。
为了计算访问www.example.com的频率,算法通过读取每行$j$的$M[j, h_j(www.example.com)]$来获取每个无偏估计,并计算这些估计的均值。
Private Hadamard Count Mean Sketch
提高带宽有提高利于CMS的准确率,但是会提高用户的传输开销。为了在减小传输开销的同时尽量降低对准确率的影响,设计了Private Hadamard Count Mean Sketch algorithm (HCMS),可以在客户端发送1比特的情况下,只有很小的准确率损失。
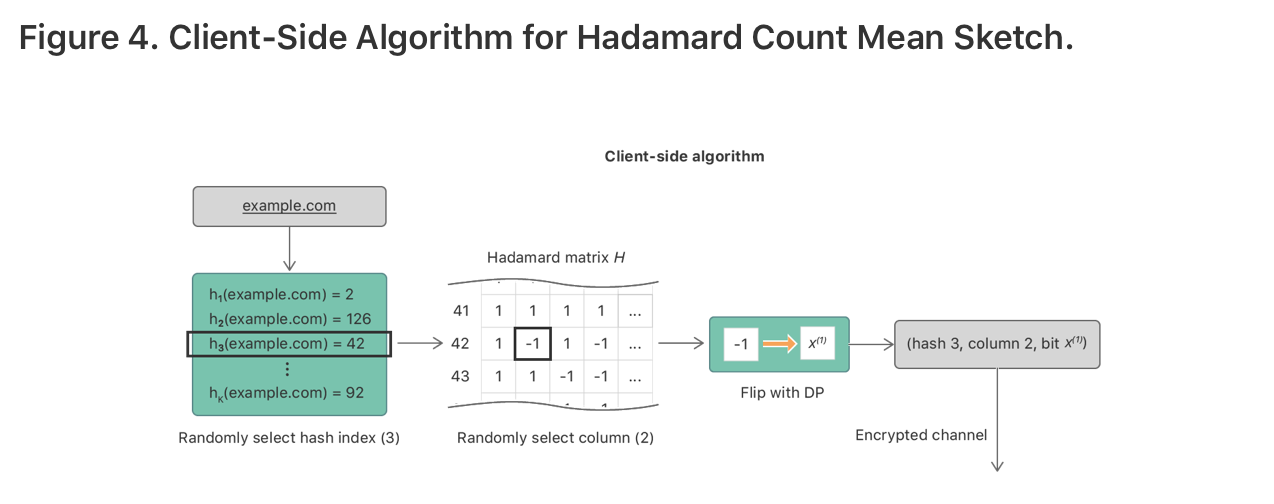
还是通过一个例子来展示HCMS算法。假设某个用户访问了网址www.example.com,在CMS中,需要从k个hash函数中随机选出一个来对网址进行编码,比如$h_3(www.example.com) = 42$。这个编码写成一个one-hot vector的形式:$\mathbb{v} = (0,0,\dots,0,1,0,\dots,0)$,1在第42个位置。由于我们想传输1个比特位,一个trivial的方案是,sample and send a random coordinate from v。但是这样显然会带来很大的误差(方差)。为了减小方差,对v采用Hadamard基础变换H,比如$\mathbb{v’} = H\mathbb{v} = (+1, -1, \dots, +1)$。从v’中随机选出a single random coordinate,对应的比特位以$\frac{1}{e^\epsilon + 1}$的概率进行翻转,来达到符合DP的目的。发送到服务器的output包括所选hash函数的index、sampled coordinate index和the privatized bit,如图4所示。
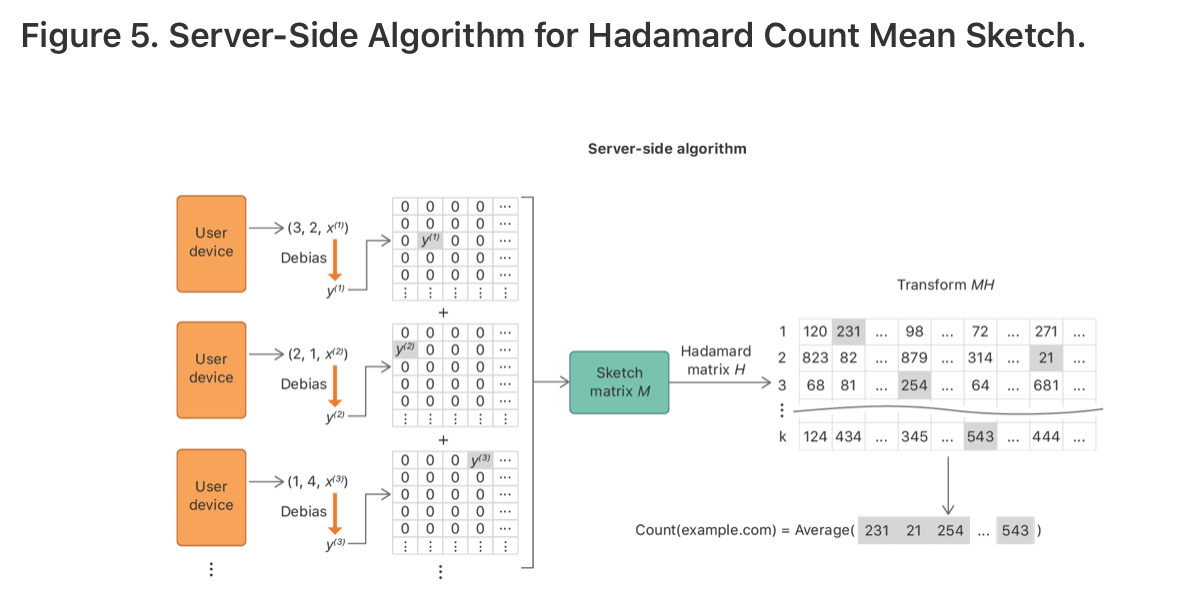
服务器端端算法和CMS类似,利用一个sketch matrix M来聚合来自客户端的隐私向量。矩阵大小是$k \times m$的。行号对应相应的hash函数的index,列号对应上述随机选出的比特位的index。第$(j,l)$个元素表示所聚合的privatized vectors是由客户端选择第$j$个hash函数和选择的第$l$个比特位。然后privatized vectors经过特定的缩放(scaled),通过逆Hadamard矩阵进行变换,还原回原先的矩阵。这一步中,矩阵的每一行提供了一个元素的频数的无偏估计。比如,为了计算www.example.com的访问频数,算法通过读取每行$j$的$M[j, h_j(www.example.com)]$来获取每个无偏估计,并计算这些估计的均值以减小方差。如图5所示。
Private Sequence Fragment Puzzle
之前的算法都假设元素字典是已知的,服务器可以通过该字典来枚举以确定相应的计数。但是在某些情况中,域的范围可能很大,这时枚举整个空间是不现实的。比如,在发现频繁输入的新单词时,即使局限于10个字母区分大小写的英语单词,也需要服务器循环至少$52^{10}$个元素。
因此设计了一种叫做Sequence Fragment Puzzle (SFP)的算法。我们利用了这样一个事实:给定一个流行的字符串,该字符串的任何子字符串也至少同样受欢迎。在设备端,我们使用客户端CMS算法对键入的单词进行隐私化。 另外,我们选择单词的子串并将其与该单词的8位hash连接。 我们将小hash称为puzzle piece,将子串与hash的拼接称为fragment。fragment同样通过CMS进行隐私化,和隐私化的单词一起发送给服务器。比如,对于单词Despacito和子串sp,客户端需要发送:CMS(Despacito),CMS(sp$\Vert$97)以及子串的位置。其中97是puzzle piece。
Using sketches for fragments, 服务器端的算法可以为每个子字符串位置的所有可能的fragments绘制一个直方图。puzzle piece可以被用来关联fragments,因为同一个单词的fragments有同样的hash值。然后,服务器端的算法通过连接puzzle piece匹配的流行fragment来确定候选字符串列表。
Then, restricting itself to the most popular fragments, the server algorithm determines a list of candidate strings by concatenating popular fragments whose puzzle pieces match. The set of candidate strings forms a dictionary of reasonable size and lets us use the CMS algorithm on the full word.
Results
举三个use cases。
Discovering Popular Emojis
我们希望确定客户最常使用哪些特定的表情符号以及这些表情的相对分布。 为CMS设定$m=1024, k=65536, \epsilon = 4$, 2600个表情符号。
(2600个表情hash到1024个值,会有冲突吧,这样不会不准确么?)

不同的键盘区域设置对表情的影响如图6.
Identifying High Energy and Memory Usage in Safari
目标是统计不同website对资源的利用。考虑两种类型的域:那些导致高内存使用的域和那些因CPU使用而导致过多能量消耗的域。 在iOS 11和macOS High Sierra中,Safari可以自动检测这些特殊域并使用差分隐私进行报告。
为HCMS设置参数$m = 32,768, k = 1024, \epsilon = 4$,字典大小是250000个web domains。
Discovering New Words
找到流行的新词汇。
Conclusion
我们已经表明,我们可以找到流行的缩写词和俚语词,流行的表情符号,流行的健康数据类型,同时满足本地差分隐私。此外,我们可以识别消耗过多能量和内存的网站,以及用户想要自动播放的网站。此信息已用于改进功能以获得用户体验。
